1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
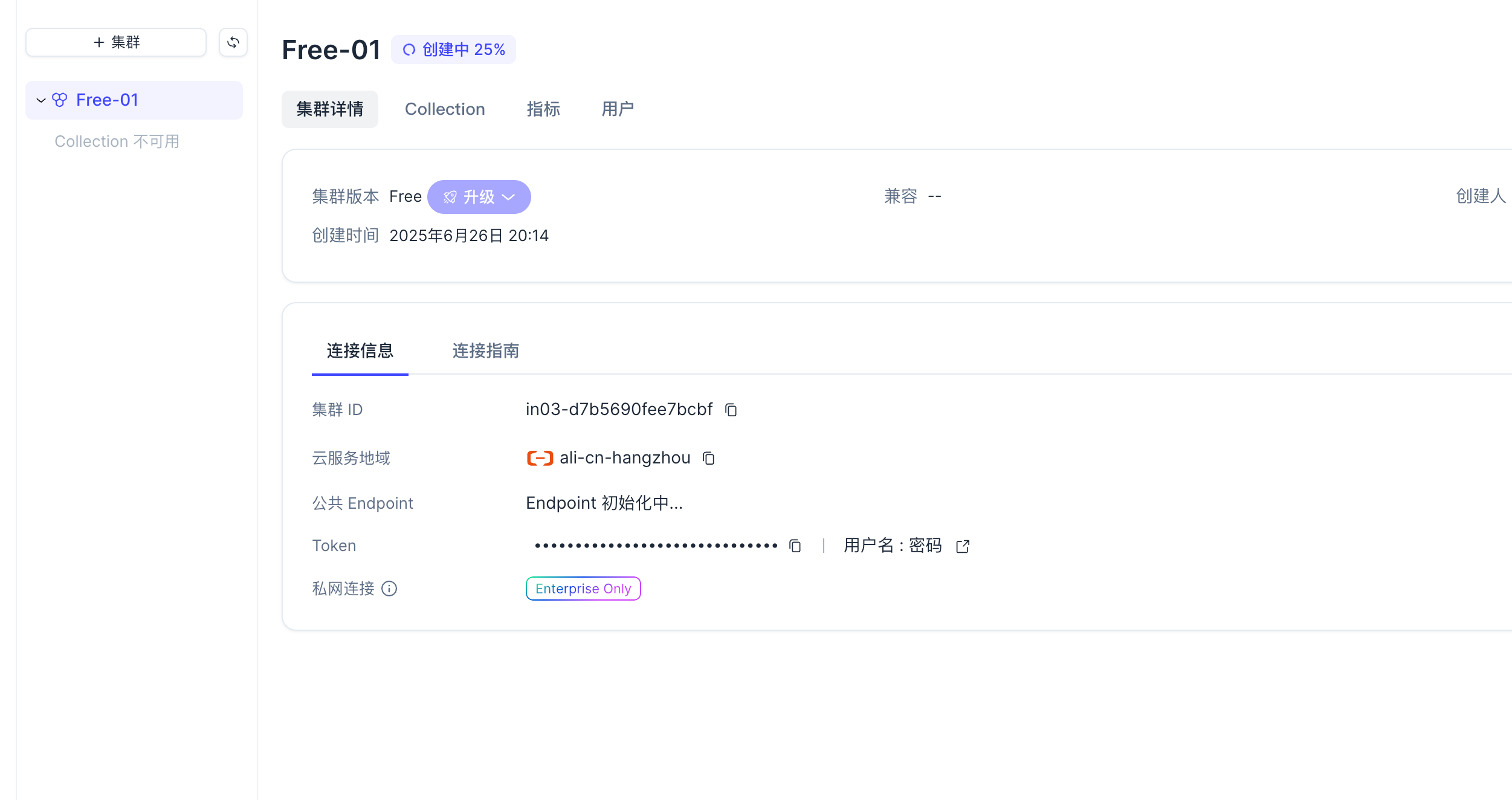
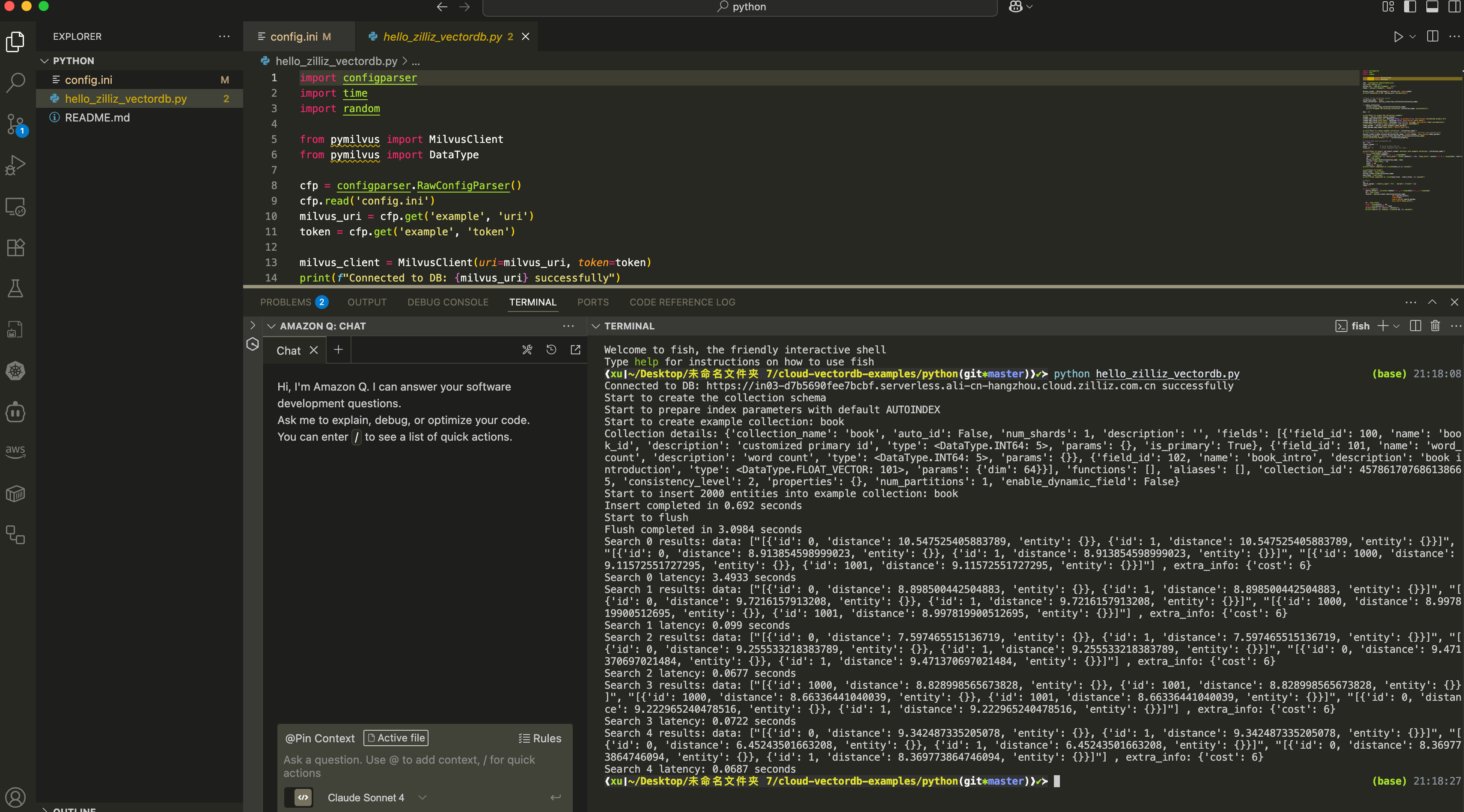
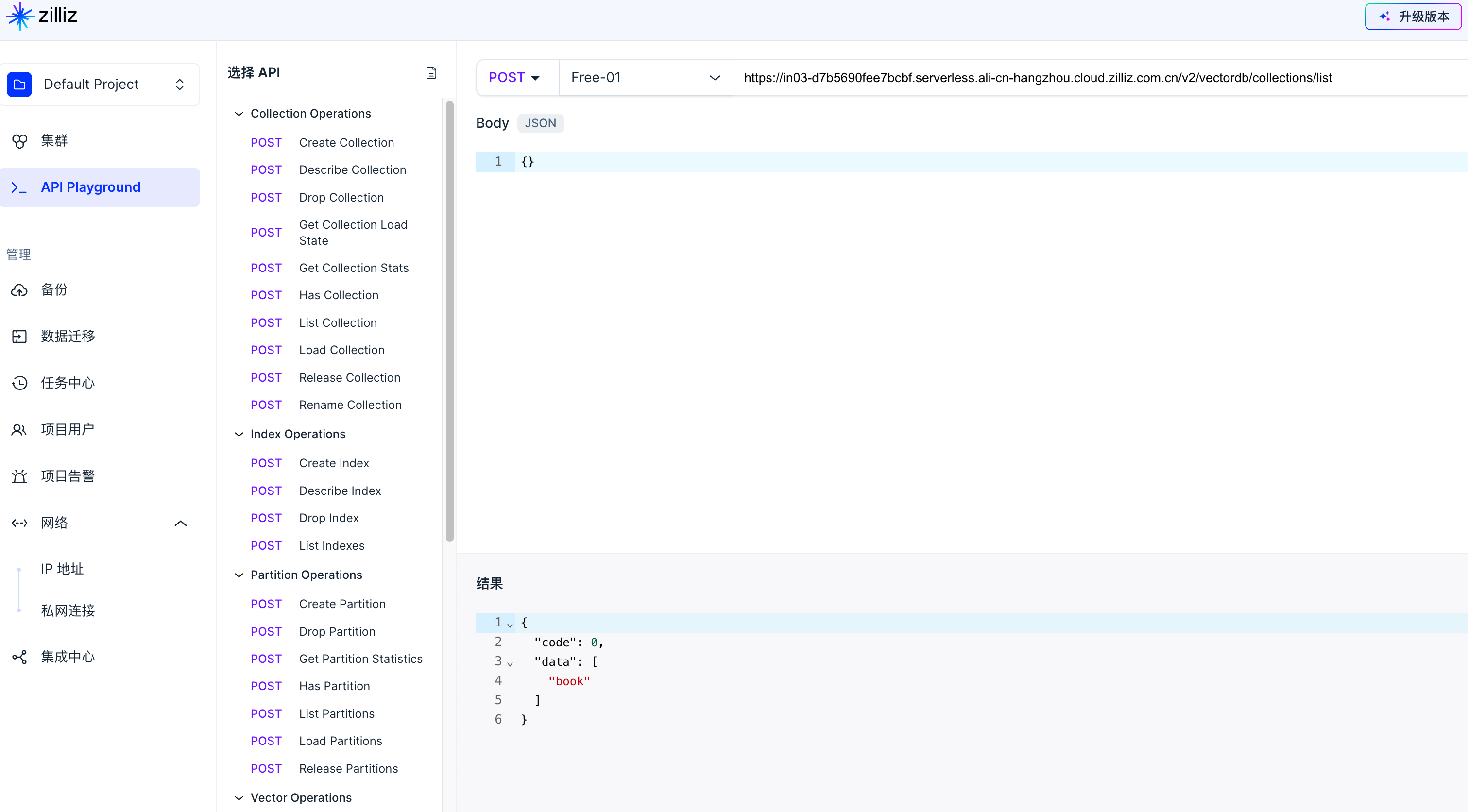
| Connected to DB: https://in03-d7b5690fee7bcbf.serverless.ali-cn-hangzhou.cloud.zilliz.com.cn successfully
Start to create the collection schema
Start to prepare index parameters with default AUTOINDEX
Start to create example collection: book
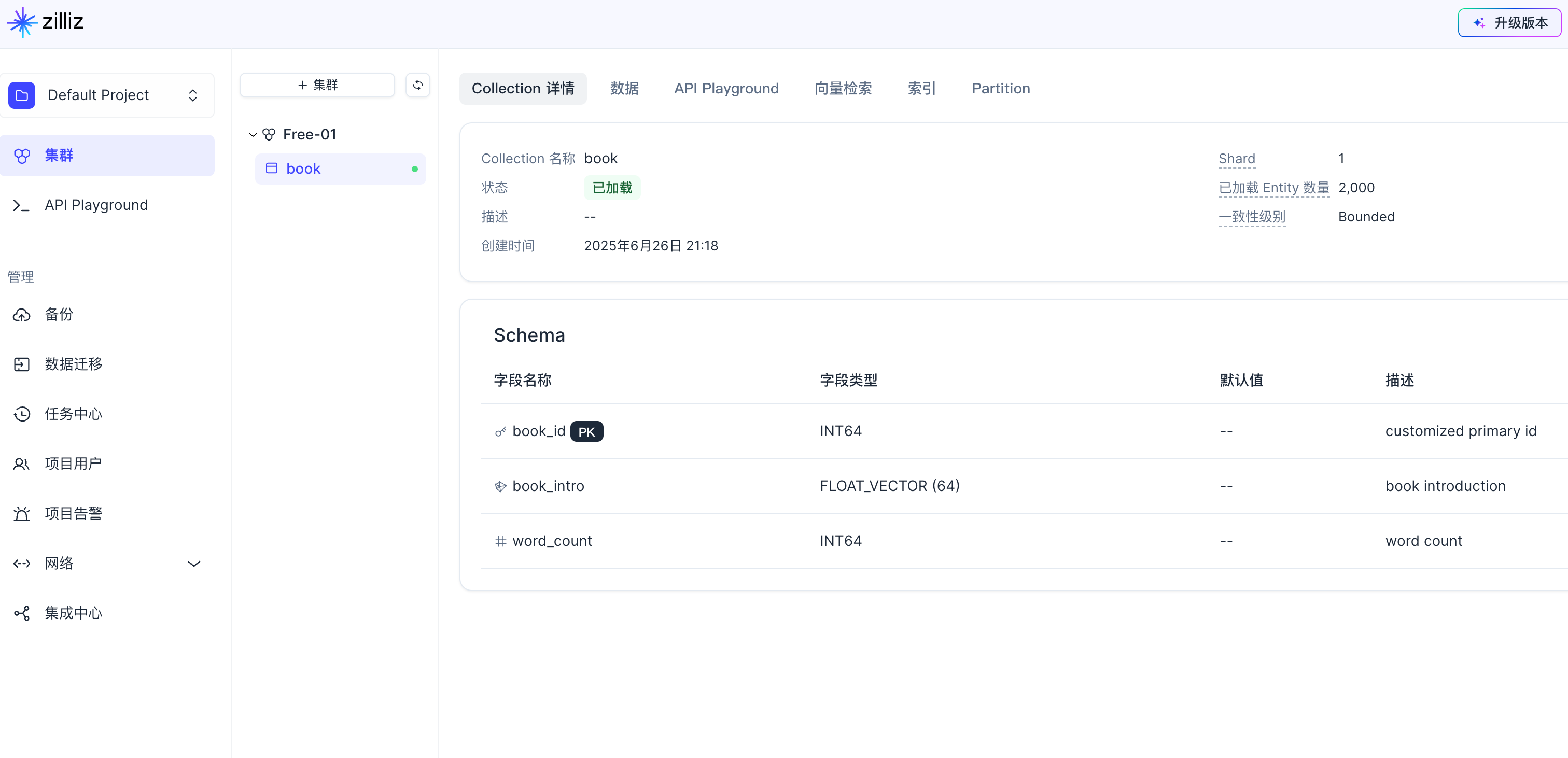
Collection details: {'collection_name': 'book', 'auto_id': False, 'num_shards': 1, 'description': '', 'fields': [{'field_id': 100, 'name': 'book_id', 'description': 'customized primary id', 'type': <DataType.INT64: 5>, 'params': {}, 'is_primary': True}, {'field_id': 101, 'name': 'word_count', 'description': 'word count', 'type': <DataType.INT64: 5>, 'params': {}}, {'field_id': 102, 'name': 'book_intro', 'description': 'book introduction', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 64}}], 'functions': [], 'aliases': [], 'collection_id': 457861707686138665, 'consistency_level': 2, 'properties': {}, 'num_partitions': 1, 'enable_dynamic_field': False}
Start to insert 2000 entities into example collection: book
Insert completed in 0.692 seconds
Start to flush
Flush completed in 3.0984 seconds
Search 0 results: data: ["[{'id': 0, 'distance': 10.547525405883789, 'entity': {}}, {'id': 1, 'distance': 10.547525405883789, 'entity': {}}]", "[{'id': 0, 'distance': 8.913854598999023, 'entity': {}}, {'id': 1, 'distance': 8.913854598999023, 'entity': {}}]", "[{'id': 1000, 'distance': 9.11572551727295, 'entity': {}}, {'id': 1001, 'distance': 9.11572551727295, 'entity': {}}]"] , extra_info: {'cost': 6}
Search 0 latency: 3.4933 seconds
Search 1 results: data: ["[{'id': 0, 'distance': 8.898500442504883, 'entity': {}}, {'id': 1, 'distance': 8.898500442504883, 'entity': {}}]", "[{'id': 0, 'distance': 9.7216157913208, 'entity': {}}, {'id': 1, 'distance': 9.7216157913208, 'entity': {}}]", "[{'id': 1000, 'distance': 8.997819900512695, 'entity': {}}, {'id': 1001, 'distance': 8.997819900512695, 'entity': {}}]"] , extra_info: {'cost': 6}
Search 1 latency: 0.099 seconds
Search 2 results: data: ["[{'id': 0, 'distance': 7.597465515136719, 'entity': {}}, {'id': 1, 'distance': 7.597465515136719, 'entity': {}}]", "[{'id': 0, 'distance': 9.255533218383789, 'entity': {}}, {'id': 1, 'distance': 9.255533218383789, 'entity': {}}]", "[{'id': 0, 'distance': 9.471370697021484, 'entity': {}}, {'id': 1, 'distance': 9.471370697021484, 'entity': {}}]"] , extra_info: {'cost': 6}
Search 2 latency: 0.0677 seconds
Search 3 results: data: ["[{'id': 1000, 'distance': 8.828998565673828, 'entity': {}}, {'id': 1001, 'distance': 8.828998565673828, 'entity': {}}]", "[{'id': 1000, 'distance': 8.66336441040039, 'entity': {}}, {'id': 1001, 'distance': 8.66336441040039, 'entity': {}}]", "[{'id': 0, 'distance': 9.222965240478516, 'entity': {}}, {'id': 1, 'distance': 9.222965240478516, 'entity': {}}]"] , extra_info: {'cost': 6}
Search 3 latency: 0.0722 seconds
Search 4 results: data: ["[{'id': 0, 'distance': 9.342487335205078, 'entity': {}}, {'id': 1, 'distance': 9.342487335205078, 'entity': {}}]", "[{'id': 0, 'distance': 6.45243501663208, 'entity': {}}, {'id': 1, 'distance': 6.45243501663208, 'entity': {}}]", "[{'id': 0, 'distance': 8.369773864746094, 'entity': {}}, {'id': 1, 'distance': 8.369773864746094, 'entity': {}}]"] , extra_info: {'cost': 6}
Search 4 latency: 0.0687 seconds
|