1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
|
"""
向量检索示例(Cohere Embed v4):Bedrock -> AOSS 写入 -> KNN 查询
与 v3 的区别:
1. 模型走 inference profile:us.cohere.embed-v4:0(不能直调 on-demand)
2. 请求需带 embedding_types + output_dimension(v4 支持 256/512/1024/1536)
3. 响应 embeddings 是 dict:{"float": [[...]]},取 ["float"] 才是向量列表
4. v4 支持多模态(文本+图像)与长上下文,这里只演示文本
依赖:
pip install boto3 opensearch-py requests-aws4auth
前提:
- 当前 AWS 凭证对 AOSS collection 有 data access policy 授权
- 对 Bedrock 的 Cohere Embed v4 inference profile 有调用权限
用法:
python3 vector_search_v4.py index # 写入(索引)示例文档
python3 vector_search_v4.py search "你的查询文本" # 语义检索
python3 vector_search_v4.py search # 不带查询词则用默认词
注意:
AOSS 写入后 KNN 图有 30~60 秒构建延迟,刚 index 完立即 search 可能返回空,
稍等再查即可。
"""
import sys
import json
import boto3
from opensearchpy import OpenSearch, RequestsHttpConnection, helpers
from requests_aws4auth import AWS4Auth
REGION = "us-west-2"
HOST = "xxxx.us-west-2.aoss.amazonaws.com"
INDEX = "vector-index-v4"
EMBED_MODEL = "us.cohere.embed-v4:0"
OUTPUT_DIM = 1024
SERVICE = "aoss"
session = boto3.Session()
cred = session.get_credentials()
awsauth = AWS4Auth(
cred.access_key, cred.secret_key, REGION, SERVICE,
session_token=cred.token,
)
client = OpenSearch(
hosts=[{"host": HOST, "port": 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
pool_maxsize=20,
)
bedrock = session.client("bedrock-runtime", region_name=REGION)
def embed(texts, input_type):
"""input_type: 'search_document'(写入) 或 'search_query'(查询)
v4 响应:{"embeddings": {"float": [[...], ...]}}"""
resp = bedrock.invoke_model(
modelId=EMBED_MODEL,
body=json.dumps({
"texts": texts,
"input_type": input_type,
"output_dimension": OUTPUT_DIM,
"embedding_types": ["float"],
}),
)
return json.loads(resp["body"].read())["embeddings"]["float"]
def index_docs():
docs = [
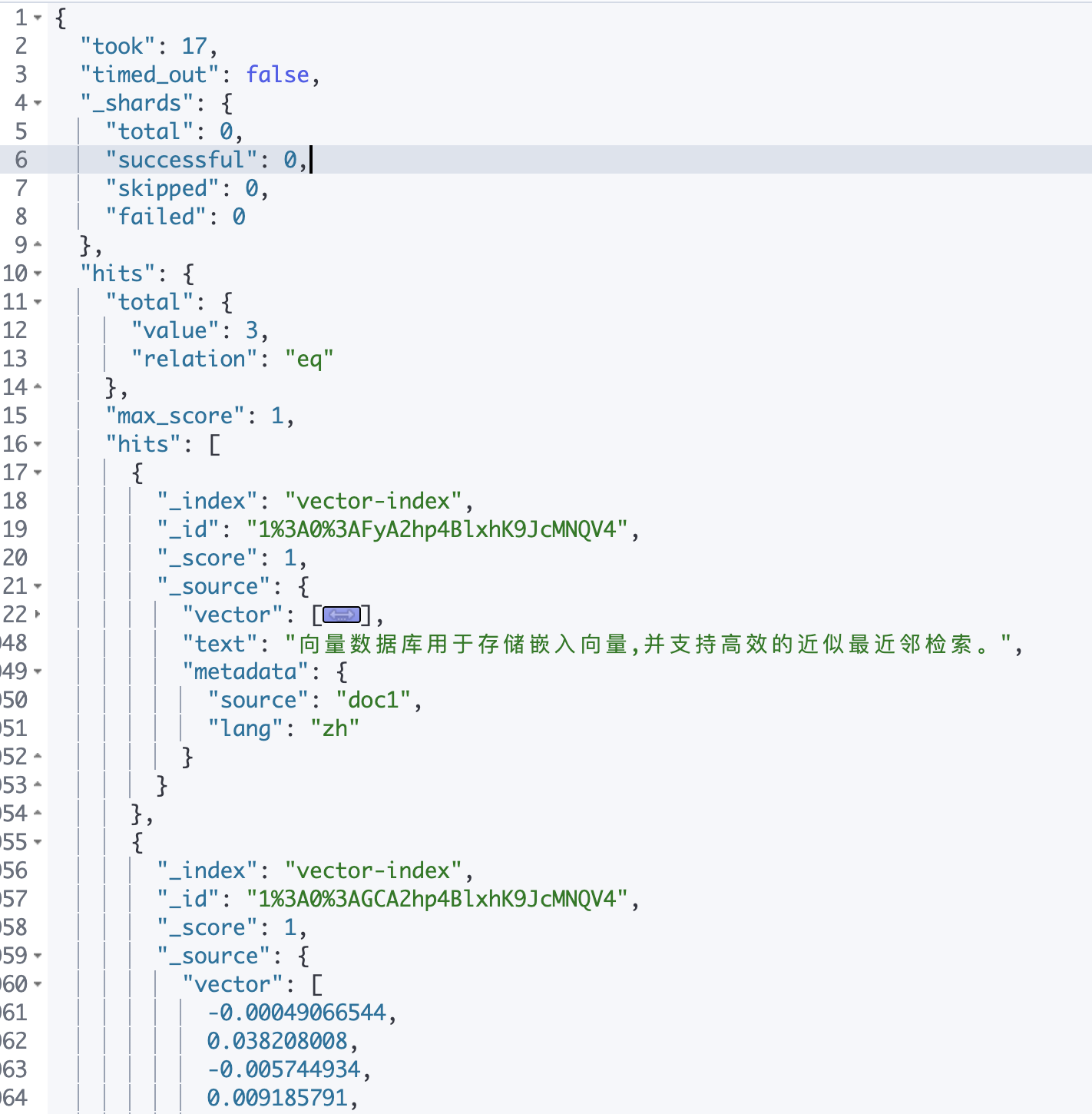
{"text": "向量数据库用于存储嵌入向量,并支持高效的近似最近邻检索。",
"metadata": {"source": "doc1", "lang": "zh"}},
{"text": "HNSW 是一种基于图的近似最近邻算法,在召回率和查询速度间取得平衡。",
"metadata": {"source": "doc2", "lang": "zh"}},
{"text": "余弦相似度通过向量夹角衡量语义相近程度,常用于文本检索。",
"metadata": {"source": "doc3", "lang": "zh"}},
]
vectors = embed([d["text"] for d in docs], "search_document")
actions = [
{"_index": INDEX, "_source": {"vector": v, "text": d["text"], "metadata": d["metadata"]}}
for d, v in zip(docs, vectors)
]
success, errors = helpers.bulk(client, actions)
print(f"写入成功 {success} 条; errors={errors}")
def search(query, k=3):
qvec = embed([query], "search_query")[0]
body = {
"size": k,
"query": {"knn": {"vector": {"vector": qvec, "k": k}}},
"_source": ["text", "metadata"],
}
res = client.search(index=INDEX, body=body)
print(f"\n查询: {query}\n")
for hit in res["hits"]["hits"]:
print(f" score={hit['_score']:.4f} {hit['_source']['text']}")
if __name__ == "__main__":
if len(sys.argv) < 2:
print(__doc__)
sys.exit(1)
cmd = sys.argv[1]
if cmd == "index":
index_docs()
elif cmd == "search":
search(sys.argv[2] if len(sys.argv) > 2 else "最近邻检索算法")
else:
print(__doc__)
|

 微信
微信 支付宝
支付宝