Elasticsearch 自动 Mapping 与 MySQL Schema 的对比分析
在企业级数据系统中,Elasticsearch(简称 ES) 与 MySQL 是两种完全不同的数据管理哲学。
一个是面向搜索与分析的分布式引擎,一个是面向事务与一致性的关系型数据库。
而当我们深入理解它们的数据结构定义方式——ES 的 自动 mapping 推断 与 MySQL 的 手动 schema 定义——就会发现,它们的核心设计理念几乎是两个世界。
本文将从机制、原理、优缺点和使用建议等角度,系统对比两者的差异,重点聚焦在 Elasticsearch 的自动 mapping 特性上。
一、什么是 Mapping 与 Schema
在 MySQL 中,我们习惯使用 表结构(Schema) 来定义数据字段及其类型:
1 | CREATE TABLE user ( |
每一行都必须严格遵守这个表结构,类型固定,字段不可缺少。
这是典型的 Schema-first 模型:在写入之前必须定义好结构。
而在 Elasticsearch 中,索引(Index)虽然也有 schema 概念,但它是通过 Mapping 来定义字段类型和分析方式的。
Mapping 可以手动声明,也可以让 ES 自动推断。例如:
1 | POST /user/_doc |
ES 会自动创建 user 索引,并根据字段值类型生成如下 mapping:
1 | { |
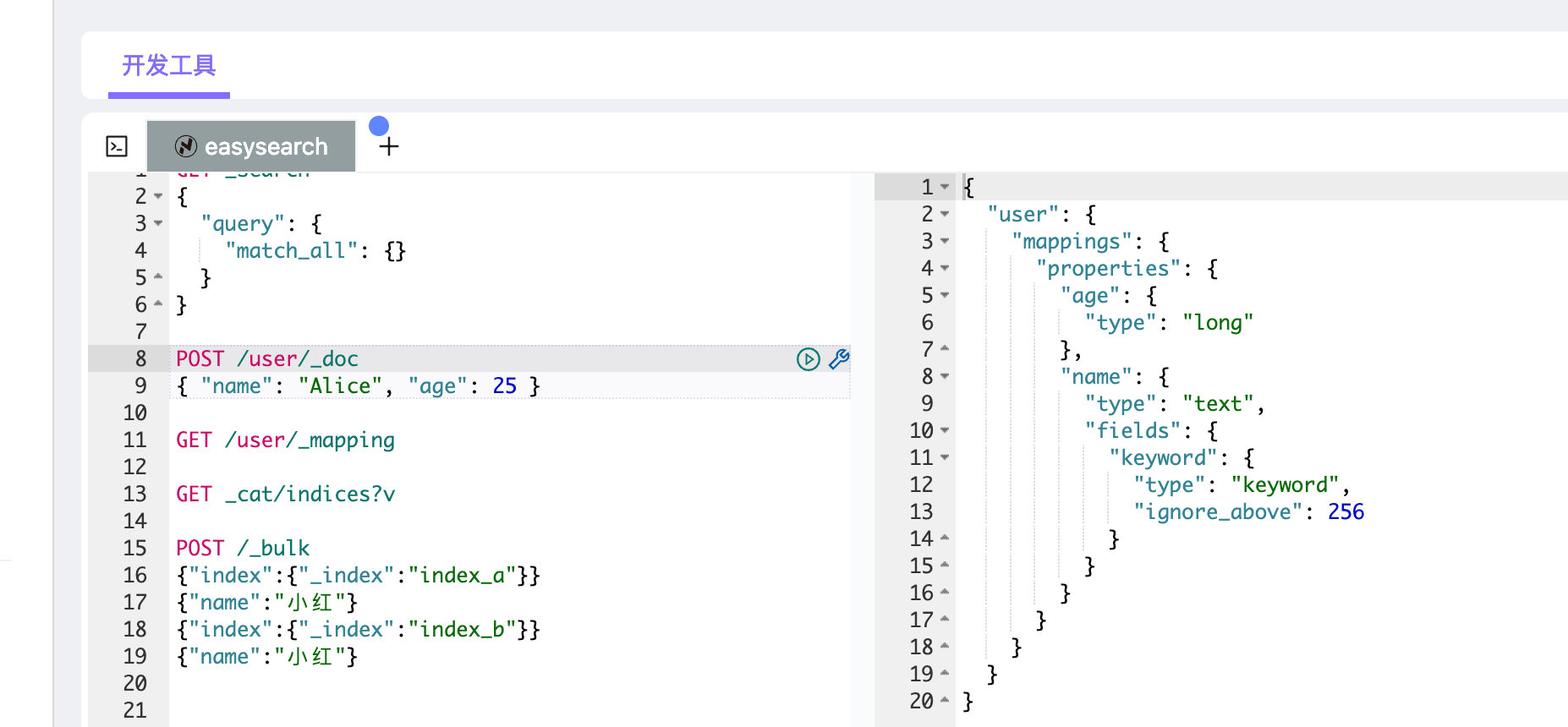
这就是 自动 mapping(dynamic mapping):ES 在第一次看到某字段时自动推断类型并写入 mapping。
不需要提前定义结构,系统“自学习”出 schema。
二、自动 Mapping 的推断机制
Elasticsearch 的 mapping 推断是动态的(Dynamic Mapping)。当写入新文档时,ES 会:
- 扫描每个字段;
- 根据字段值的类型判断(string、number、boolean、date 等);
- 将结果写入
_mapping; - 更新索引元数据并持久化。
例如:
| 值 | 推断类型 | 备注 |
|---|---|---|
"hello" |
text + keyword | 同时支持全文检索与精确匹配 |
123 |
long | 数值型 |
12.3 |
double | 浮点型 |
"2025-10-05" |
date | 自动识别日期格式 |
true |
boolean | 布尔值 |
ES 的这种自动识别让开发者在数据探索早期几乎零配置即可使用,非常便捷。
但这种便捷背后也隐藏着风险——错误推断、类型冲突、mapping 爆炸等问题可能在后期放大。
三、MySQL 的 Schema 定义机制
与 ES 不同,MySQL 属于 强类型、静态结构 模型。
它要求所有字段在写入前就被定义好。任何表结构变更都需要执行 ALTER TABLE,会产生锁表或重建索引的代价。
优点是:
- 数据一致性强;
- 结构清晰;
- 易于维护和优化;
- 支持事务与约束。
缺点则是:
- 演进成本高;
- 扩展不灵活;
- 对半结构化数据支持差。
如果说 MySQL 的 schema 是“一座刚性大厦”,那 ES 的 mapping 就像“可随时扩建的集装箱”。
四、自动 Mapping 的优势:灵活与速度
1. 开发效率高
在日志、埋点、IoT 等场景中,数据字段极多且经常变化。
自动 mapping 让开发者无需提前规划字段,只要把 JSON 写进去,ES 就能立刻索引和查询。
例如日志:
1 | { "host": "server-1", "response_time": 123, "status": 200 } |
即使第二条日志多了新字段:
1 | { |
ES 也会自动为 region 增加字段定义,无需手动修改 mapping。
这在 MySQL 中则必须执行结构变更。
2. 兼容性好
ES 的索引不要求所有文档字段一致。某些文档可以缺字段而不影响写入。
对动态 JSON 数据、日志、监控事件特别友好。
3. 适配性强
数据可来自多源系统(API、Kafka、日志流),字段差异大。
自动 mapping 让这些异构数据能快速进入索引,后期再统一分析。
4. 快速原型构建
在数据探索阶段,不必先定义 schema,就能立刻搜索和聚合,是数据科学家和分析工程师最喜欢的特性之一。
五、自动 Mapping 的风险与缺陷
1. 类型误判(Type Guessing)
ES 根据值内容推断类型,但不是总能猜对:
| 原始值 | 被推断类型 | 潜在问题 |
|---|---|---|
"00123" |
text | 实际上是字符串数字 |
"2024/12/01" |
date | 格式异常可能被误识别 |
123.0 |
double | 实际希望 long,却被识别为浮点 |
true / false |
boolean | 可能来自字符串而非布尔值 |
类型一旦被推断并写入 mapping,就无法修改。
如果写错,只能重建索引并重新导入数据。
2. Mapping Explosion(映射爆炸)
ES 的每个字段都要占用堆内存(field data、倒排索引、统计信息)。
当系统存在动态命名字段(如 user_1, user_2, …)时,会生成成千上万个字段,导致:
- Mapping 文件膨胀;
- 节点 heap 占用急剧上升;
- 查询性能下降;
- 甚至引发 “too many fields” 异常。
官方建议:单个索引字段数不要超过 1000。
3. 类型不可变
ES 中字段一旦创建,类型就锁定。
比如第一次写入 "price": "123" 被识别为 text,之后再写入数字 price: 123 就会报错:
1 | mapper_parsing_exception: cannot merge a field of type [long] with [text] |
修复方法只有一个:重建索引。
4. 搜索分析不准确
自动 mapping 对 string 默认生成 text + keyword 两种字段。
在全文检索时 OK,但在聚合、排序、精确匹配时会引发困惑。
许多用户在 Kibana 中查询 "region.keyword" 才能聚合,是由 mapping 自动生成机制决定的。
六、MySQL 的优势:可控与稳定
相比之下,MySQL 的 schema 固定、类型严格,所有字段定义都在 DBA 控制下。
这意味着:
- 任何类型变化都是显式的;
- 查询结果一致性强;
- 可维护性高;
- 性能优化空间大。
在交易、账务、库存、财务等场景中,MySQL 的稳定性远胜 ES。
它的缺点恰恰是 ES 的优点:灵活性差但可控。
七、如何平衡:让自动 mapping 可控
ES 提供了几种方式,在保留灵活性的同时减少风险。
1. 动态模板(Dynamic Templates)
你可以为自动推断加“模板规则”:
1 | { |
这样所有 _id 结尾的字段都被强制识别为 keyword,而不是 text。
2. 关闭自动 mapping
在生产环境常见做法是:
1 | { "dynamic": "strict" } |
意味着:未定义字段禁止写入。
防止误导入数据结构。
3. 限制字段数
1 | PUT /my_index/_settings |
避免 mapping explosion。
4. 明确控制核心字段
对关键字段(时间戳、数值、地理位置、ID)手动声明类型。
剩余部分交由 dynamic mapping 自动处理,可兼顾灵活与安全。
八、性能与存储影响对比
| 指标 | Elasticsearch | MySQL |
|---|---|---|
| 写入性能 | 较高(分布式、异步) | 较低(事务同步) |
| 读取性能 | 适合全文检索、聚合分析 | 适合主键查询、范围查询 |
| schema 变更成本 | 无(自动) | 高(需 ALTER) |
| 内存消耗 | 较大(索引元数据) | 较小 |
| 数据一致性 | 弱一致 | 强一致 |
| 横向扩展性 | 强 | 中等 |
结论:
ES 的自动 mapping 提供了极高的写入灵活性,但代价是索引元数据膨胀、内存占用高、类型错误风险大。
MySQL 的 schema 则更适合结构化、高一致性业务。
九、使用建议:什么时候用自动 mapping?
| 场景 | 建议 |
|---|---|
| 日志、监控、埋点 | ✅ 开启自动 mapping(dynamic=true) |
| 搜索引擎、用户画像 | ✅ 自动 mapping + 动态模板 |
| 电商订单、金融账务 | ❌ 手动 mapping(dynamic=strict) |
| 混合型数据(部分稳定、部分动态) | ⚙️ 手动定义核心字段 + 动态模板控制扩展字段 |
| MySQL → ES 同步 | 🚫 禁止自动 mapping,使用 Logstash/ETL 生成预定义 mapping |
十、总结:灵活与秩序的取舍
| 维度 | Elasticsearch 自动 Mapping | MySQL Schema |
|---|---|---|
| 定义方式 | 自动推断 | 手动定义 |
| 灵活性 | 极高 | 低 |
| 一致性 | 弱 | 强 |
| 修改成本 | 低(但错误代价高) | 高(但可控) |
| 可维护性 | 中等(需监控 mapping 爆炸) | 高 |
| 适用场景 | 搜索、日志、非结构化数据 | 交易、财务、结构化数据 |
Elasticsearch 的自动 mapping 是一把双刃剑:
它让数据“随写随用”,带来极大的灵活性;
但同时,也可能在规模化阶段埋下类型混乱、性能下降的隐患。
最佳实践是在项目早期利用其灵活性快速构建原型;
而在生产阶段,结合手动 mapping 与动态模板,建立“半自动、可控”的数据模型。
真正成熟的 ES 使用者,从来不会完全依赖自动 mapping。
自动化是起点,不是终点;灵活性需要以控制为前提。