你有一个现成的 Flask API,想部署到 AWS Lambda 享受 Serverless 的好处,但又不想改代码?AWS Lambda Web Adapter 可以帮你实现。
本文将手把手教你如何使用 Docker + Gunicorn + Lambda Web Adapter,将 Flask 应用部署到 Lambda,并通过 API Gateway 对外提供服务。
为什么选择这个方案?
传统方式部署 Flask 到 Lambda 需要使用 Mangum、aws-wsgi 等第三方库,需要修改代码添加 handler。而 Lambda Web Adapter 是 AWS 官方方案,有以下优势:
- 零代码改动:Flask 代码完全不用改
- 生产级配置:可以使用 Gunicorn 作为 WSGI 服务器
- 本地开发友好:同一个 Docker 镜像本地和 Lambda 都能跑
- 框架无关:Flask、Django、FastAPI 都支持
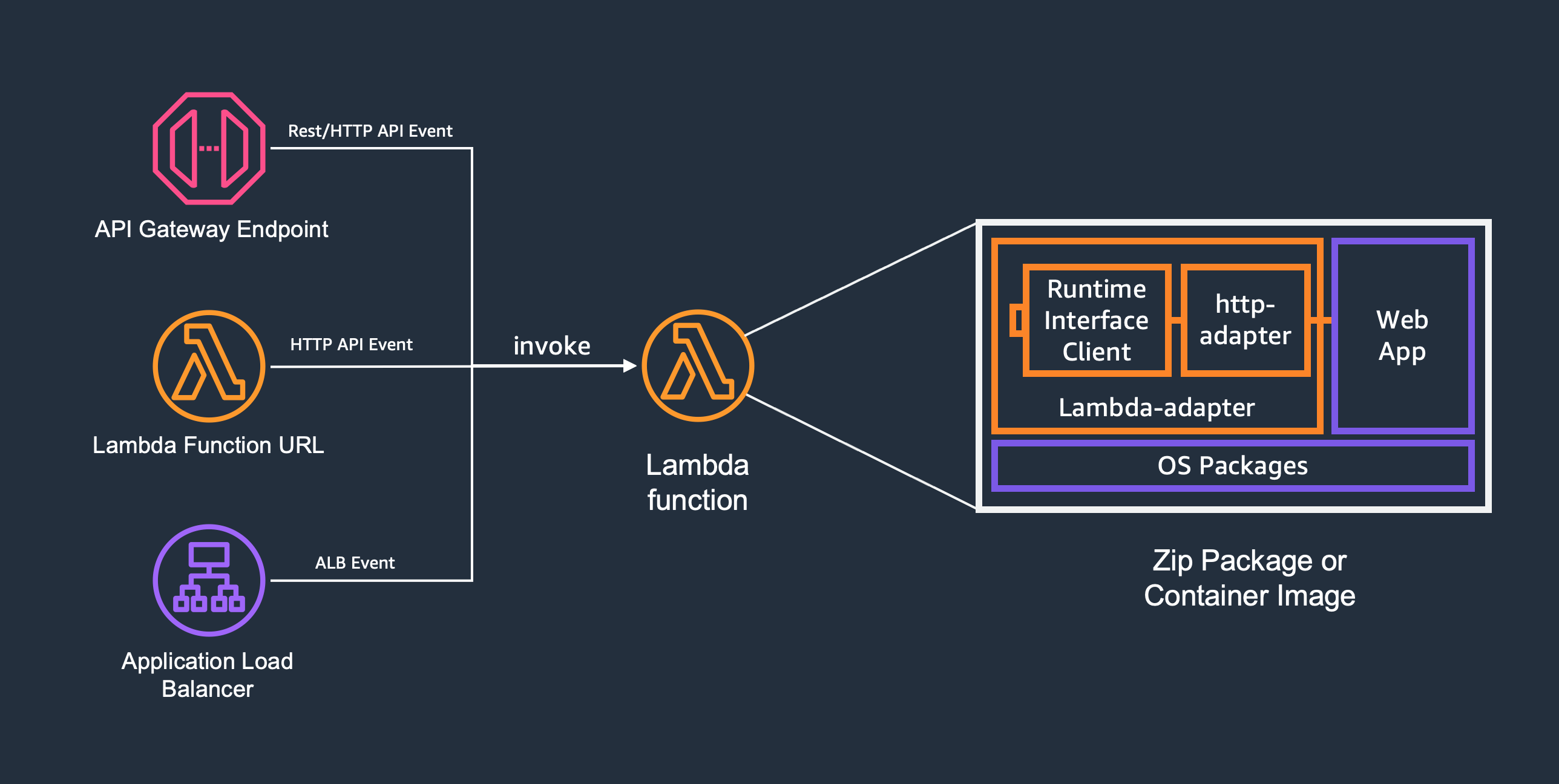
架构概览
1
2
3
4
5
| 客户端 → API Gateway → Lambda (Docker 容器)
↓
Lambda Web Adapter
↓
Gunicorn + Flask
|
Lambda Web Adapter 作为 Lambda Extension 运行,负责将 API Gateway 事件转换为标准 HTTP 请求,Flask 应用完全感知不到自己运行在 Lambda 上。
准备工作
确保你已安装:
- Docker
- AWS CLI(已配置凭证)
- Python 3.11+
第一步:创建 Flask 应用
创建项目目录和文件:
1
| mkdir flask-lambda && cd flask-lambda
|
app.py - 一个简单的 Flask API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from flask import Flask, jsonify, request
app = Flask(__name__)
@app.route('/')
def health():
return jsonify(status='healthy')
@app.route('/api/hello')
def hello():
name = request.args.get('name', 'World')
return jsonify(message=f'Hello, {name}!')
@app.route('/api/echo', methods=['POST'])
def echo():
data = request.get_json()
return jsonify(received=data)
|
requirements.txt:
1
2
| flask==3.0.0
gunicorn==21.2.0
|
第二步:配置 Gunicorn
gunicorn.conf.py - 针对 Lambda 优化的配置:
1
2
3
4
5
6
7
8
| bind = '0.0.0.0:8080'
workers = 1
threads = 4
timeout = 30
keepalive = 2
accesslog = '-'
errorlog = '-'
loglevel = 'info'
|
第三步:编写 Dockerfile
Dockerfile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| FROM python:3.11-slim
COPY --from=public.ecr.aws/awsguru/aws-lambda-adapter:0.9.1 /lambda-adapter /opt/extensions/lambda-adapter
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8080
CMD ["gunicorn", "-c", "gunicorn.conf.py", "app:app"]
|
核心就是这一行 COPY --from=...,它从 AWS 公共 ECR 仓库拉取 Lambda Web Adapter 二进制文件,放到 /opt/extensions/ 目录。Lambda 启动时会自动加载这个 Extension。
第四步:本地测试
构建前先登录 ECR Public:
1
2
| aws ecr-public get-login-password --region us-east-1 | \
docker login --username AWS --password-stdin public.ecr.aws
|
构建并运行:
1
2
| docker build --platform linux/amd64 -t flask-lambda .
docker run -p 8080:8080 flask-lambda
|
测试:
1
2
3
4
5
6
7
8
9
10
| curl http://localhost:8080/
curl "http://localhost:8080/api/hello?name=Lambda"
curl -X POST http://localhost:8080/api/echo \
-H "Content-Type: application/json" \
-d '{"msg":"hello"}'
|
本地没问题,接下来部署到 AWS。
第五步:推送镜像到 ECR
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
AWS_REGION="ap-northeast-1"
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
ECR_REPO="flask-lambda"
aws ecr create-repository --repository-name $ECR_REPO --region $AWS_REGION
aws ecr get-login-password --region $AWS_REGION | \
docker login --username AWS --password-stdin \
$AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com
docker tag flask-lambda:latest \
$AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO:latest
docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO:latest
|
第六步:创建 Lambda 函数
首先创建 IAM 角色:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
cat > trust-policy.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "lambda.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
EOF
aws iam create-role \
--role-name flask-lambda-role \
--assume-role-policy-document file://trust-policy.json
aws iam attach-role-policy \
--role-name flask-lambda-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
sleep 10
|
创建 Lambda 函数:
1
2
3
4
5
6
7
8
| aws lambda create-function \
--function-name flask-api \
--package-type Image \
--code ImageUri=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO:latest \
--role arn:aws:iam::$AWS_ACCOUNT_ID:role/flask-lambda-role \
--timeout 30 \
--memory-size 512 \
--region $AWS_REGION
|
第七步:配置 API Gateway
打开 API Gateway 控制台,创建 REST API:
- 点击「创建 API」→ 选择「REST API」→「构建」
- 输入 API 名称,如
flask-api
- 创建资源:
- 点击「创建资源」
- 勾选「代理资源」
- 资源路径填
{proxy+}
- 点击「创建资源」
- 设置集成:
- 集成类型选「Lambda 函数」
- 勾选「Lambda 代理集成」
- 选择你的 Lambda 函数
flask-api
- 同样为根路径
/ 创建 ANY 方法,集成到同一个 Lambda
- 点击「部署 API」,阶段名填
v1
部署完成后,你会得到一个调用 URL,类似:
1
| https://xxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1
|
第八步:测试 API
1
2
3
4
5
6
7
| API_URL="https://xxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1"
curl $API_URL/
curl "$API_URL/api/hello?name=Serverless"
|
🎉 大功告成!你的 Flask API 已经运行在 Lambda 上了。
进阶:IAM 认证
如果你的 API 需要认证,可以在 API Gateway 中启用 IAM 认证。调用时需要对请求进行 SigV4 签名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import boto3
from botocore.auth import SigV4Auth
from botocore.awsrequest import AWSRequest
import requests
def signed_request(method, url, data=None, headers=None):
session = boto3.Session()
credentials = session.get_credentials()
headers = headers or {}
request = AWSRequest(method=method, url=url, data=data, headers=headers)
SigV4Auth(credentials, "execute-api", "ap-northeast-1").add_auth(request)
return requests.request(
method=method,
url=url,
headers=dict(request.headers),
data=data
)
resp = signed_request("GET", f"{API_URL}/api/hello")
print(resp.json())
|

更新部署
代码更新后,只需重新构建镜像并更新 Lambda:
1
2
3
4
5
6
7
| docker build --platform linux/amd64 -t flask-lambda .
docker tag flask-lambda:latest $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO:latest
docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO:latest
aws lambda update-function-code \
--function-name flask-api \
--image-uri $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO:latest
|
冷启动优化
首次请求可能需要 1-2 秒(冷启动),可以通过以下方式优化:
- 启用 Provisioned Concurrency:预热实例,消除冷启动
- 减小镜像体积:使用 slim 基础镜像,减少依赖
- 启用异步初始化:设置环境变量
AWS_LWA_ASYNC_INIT=true
总结
使用 Lambda Web Adapter,你可以:
- 保持 Flask 代码不变
- 使用熟悉的 Gunicorn 生产配置
- 同一镜像本地和云端都能运行
- 享受 Serverless 的弹性伸缩和按需付费
参考资料