在AWS EC2 上从零搭建 Kubernetes 集群(kubeadm)
今天讲解在AWS EC2 上使用kubeadm搭建Kubernetes 集群。
kubeadm 是 Kubernetes 官方提供的集群引导工具,用来快速创建符合最佳实践的 K8s 集群。除了初始化集群,它还能做节点的升级、降级等生命周期管理。用 kubeadm 建集群是学习 K8s 的推荐方式,也适合搭建小规模集群或作为更复杂企业级方案的基础组件。
本文基于 Ubuntu,使用三台 EC2 实例:一台作为控制面(Master),两台作为工作节点(Worker)。
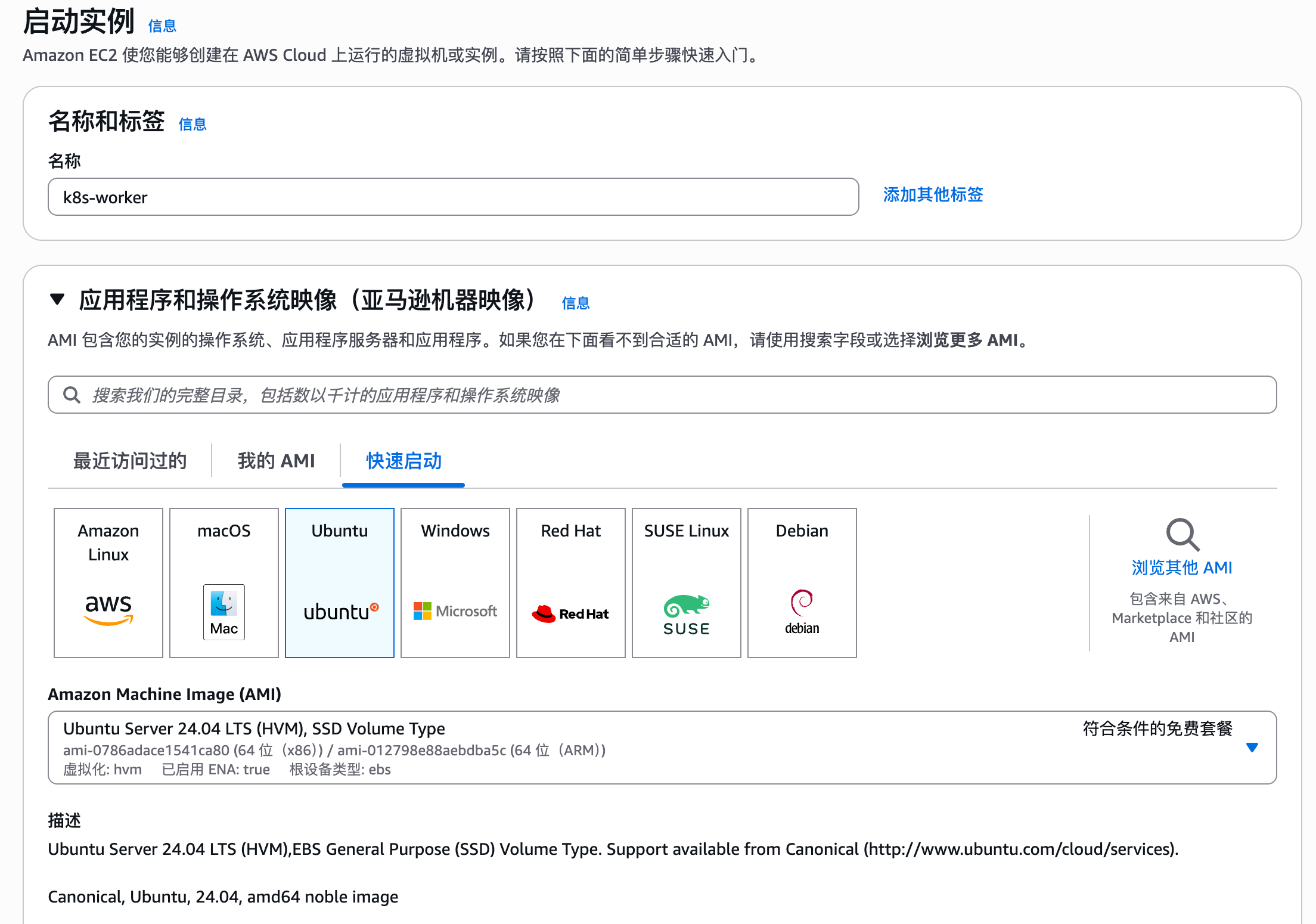
我们会在 Master 节点上从头安装 kubeadm 及其依赖,然后初始化集群,最后把 Worker 节点加入进来。
这几台 EC2 使用同一个安全组,入站规则只放行VPC网段和终端访问地址。
第一步:安装 kubeadm 及其依赖
以下操作在 Master 节点上执行(Worker 节点如果还没装也要跑一遍)。
1. 关闭 swap
kubelet 需要精确管理 Pod 的内存,swap 会让内存数据不准确,导致调度器做出错误判断。kubelet 默认检测到 swap 开着就拒绝启动。
1 | # 关闭 swap |
验证:free -h,Swap 行全是 0 就对了。
1 | ubuntu@ip-172-31-27-240:~$ free -h |
2. 更新包管理器,安装基础依赖
更新 apt 包索引,安装通过 HTTPS 访问软件仓库所需的包:
1 | sudo apt-get update |
3. 加载内核模块,允许 IPv4 转发
加载 overlay 和 br_netfilter 两个内核模块。overlay 是 containerd 存储驱动需要的,br_netfilter 让 bridge 上的流量能经过 iptables 规则,K8s 的 Service 和 NetworkPolicy 都依赖这个。
1 | sudo modprobe overlay |
4. 设置内核网络参数
让 Linux 节点的 iptables 能正确处理桥接流量。三个参数缺一不可:
bridge-nf-call-iptables:bridge 流量过 iptables,Service 转发靠这个ip_forward:开启 IP 转发,Pod 跨节点通信需要bridge-nf-call-ip6tables:同上,IPv6 版本
1 | cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf |
5. 安装 containerd
使用 Docker 官方分发的 DEB 包安装 containerd 作为容器运行时。这只是安装 containerd 的方式之一,也可以从源码编译或用其他包管理器。
1 | curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg |
6. 配置 systemd cgroup 驱动
生成 containerd 默认配置,然后把 cgroup 驱动改成 systemd。这一步是为了避免系统里同时存在两个 cgroup 管理器(systemd 和 cgroupfs)导致的不稳定问题。kubelet 默认用 systemd,containerd 也要对齐。
1 | sudo mkdir -p /etc/containerd |
7. 安装 kubeadm、kubelet、kubectl
从 Kubernetes 官方包仓库安装。三个组件的作用:
kubeadm:集群引导工具,负责 init 和 joinkubelet:每个节点上的代理,负责管理 Pod 和容器kubectl:命令行工具,用来操作集群
下面以 v1.30 为例。如果要装其他版本(比如 v1.35),把两处 v1.30 都改成 v1.35 就行,GPG key 和源地址的版本号要一致。可用版本列表见 https://pkgs.k8s.io/core:/stable:/
1 | curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg |
8. 锁定版本,防止自动升级
K8s 组件版本需要严格对齐,自动升级可能导致版本不一致出问题:
1 | sudo apt-mark hold kubelet kubeadm kubectl |
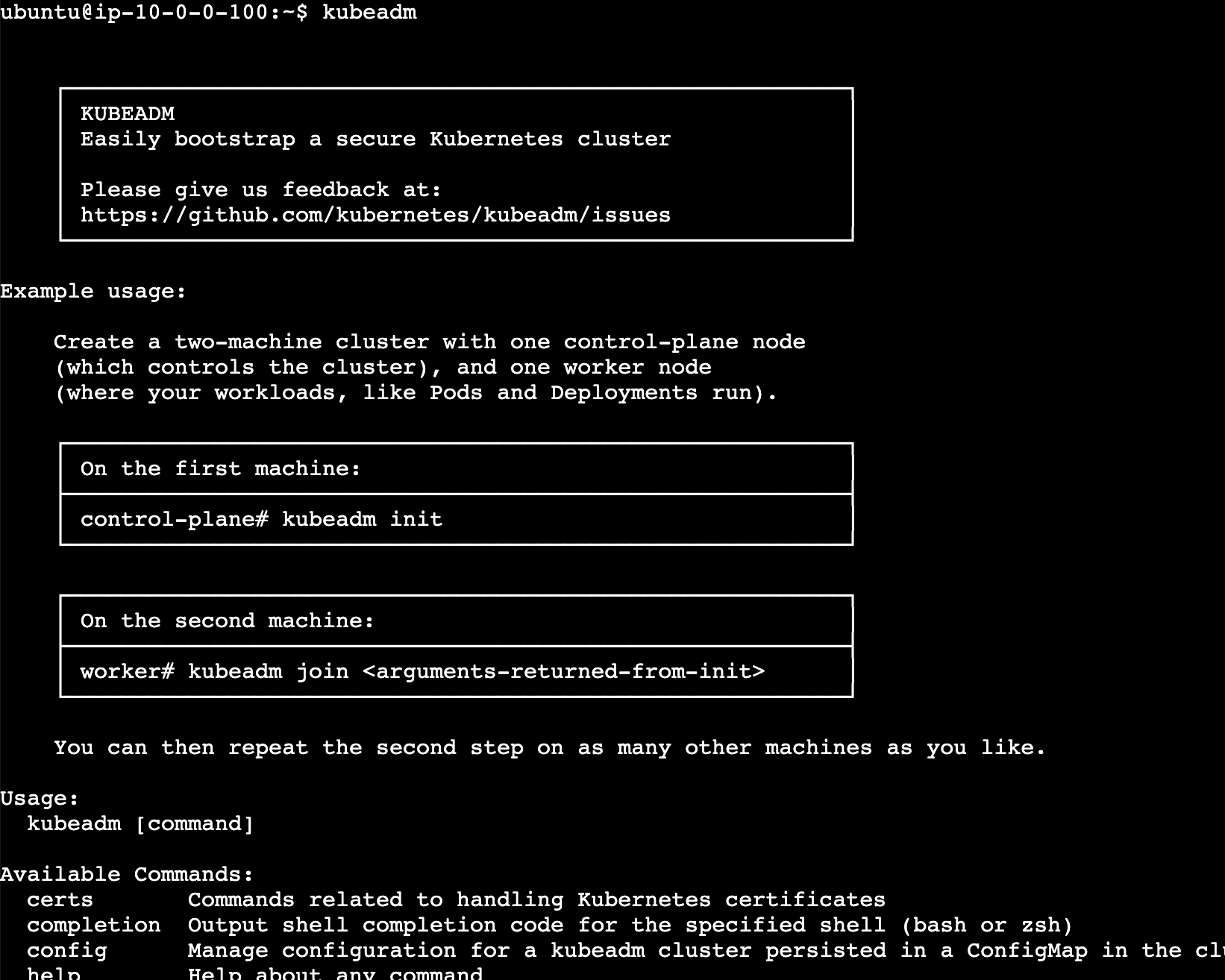
第二步:初始化控制面节点
以下操作仅在 Master 节点执行。
初始化过程会完成以下事情:
- 创建证书颁发机构(CA),用于集群内的安全通信和身份认证
- 启动节点组件:kubelet
- 启动控制面组件:API Server、Controller Manager、Scheduler、etcd
- 安装通用插件:kube-proxy、DNS
kubeadm 初始化使用合理的默认值,遵循最佳实践。当然也有很多配置选项可以自定义,比如使用自己的 CA 证书或外部 etcd 存储。
kubeadm 不会帮你安装网络插件,这个需要自己装。我们用 Calico 作为 Pod 网络插件。Calico 支持 Kubernetes NetworkPolicy,也是 AWS、Azure、GCP 的托管 K8s 服务内部使用的网络方案,生产可用。为了让 Calico 的网络策略正常工作,初始化时必须通过 --pod-network-cidr 指定 Pod 网络的 IP 范围。
1. 初始化控制面
1 | sudo kubeadm init --pod-network-cidr=192.168.0.0/16 |
192.168.0.0/16 是 Calico 的默认网段。注意这个网段不能跟你的 VPC 网络 CIDR 重叠,如果重叠了需要额外配置 Calico 来避免冲突。
输出会显示 kubeadm 初始化控制面的每一步。最后会给出两个重要信息:配置 kubectl 的命令和 worker 节点加入集群的 join 命令。
2. 保存 join 命令
把输出最后的 kubeadm join ... 命令复制下来存好,后面 worker 节点加入集群要用。token 默认 24 小时过期,过期了可以用 kubeadm token create --print-join-command 重新生成。
3. 配置 kubectl
用 kubeadm 生成的 admin kubeconfig 初始化 kubectl 配置:
1 | mkdir -p $HOME/.kube |
4. 确认控制面组件状态
1 | kubectl get componentstatuses |
输出应该显示 scheduler、controller-manager、etcd 都是 Healthy。kubectl 能正常返回结果也说明 API Server 在正常工作。
5. 查看节点状态
1 | kubectl get nodes |
这时候控制面节点会显示 NotReady。这是正常的——因为还没装网络插件。
1 | NAME STATUS ROLES AGE VERSION |
可以用 kubectl describe nodes 看详细信息,Conditions 里会显示 Ready: False,原因是 “network plugin is not ready”,CNI(Container Network Interface)还没初始化。
6. 安装 Calico 网络插件(Operator 方式)
Calico 有两种安装方式:Operator 和 Manifest。官方现在推荐 Operator 方式,通过 Tigera Operator 来管理 Calico 的生命周期,后续升级和配置变更都更方便。
先装 Tigera Operator:
1 | kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.29.0/manifests/tigera-operator.yaml |
再装 Calico 自定义资源:
1 | kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.29.0/manifests/custom-resources.yaml |
custom-resources.yaml 里默认的 Pod CIDR 是 192.168.0.0/16,跟 kubeadm init 时指定的一致。如果你用了不同的 CIDR,需要先下载这个文件改 cidr 字段再 apply。
这会创建一系列资源来支持 Pod 网络,包括:
- Tigera Operator Deployment,负责管理 Calico 组件的部署和升级
- 一个 DaemonSet,在集群每个节点上运行一个 calico-node Pod
- 多个 CRD(自定义资源定义),扩展 K8s API 来支持网络策略等功能
Calico 组件会部署在 calico-system namespace 下(Operator 方式),而不是 kube-system(Manifest 方式)。
7. 等待节点就绪
1 | watch kubectl get nodes |
1 |
|
网络插件初始化完成后,控制面节点会变成 Ready。可能需要等一分钟左右。按 Ctrl+C 停止 watch。
第三步:Worker 节点加入集群
以下操作在 Worker 节点执行。
使用 kubeadm 添加工作节点比初始化控制面还要简单,一条 join 命令就搞定。
1. 连接到 Worker 节点
打开一个新终端,SSH 连接到 Worker 节点(用户名 ubuntu)。
2. 执行 join 命令
用 sudo 加上之前从 kubeadm init 输出中保存的 join 命令:
1 | sudo kubeadm join 10.0.0.100:6443 \ |
如果 token 过期了(24 小时有效),在 Master 上重新生成:
1 | kubeadm token create --print-join-command |
3. 确认 Worker 节点加入集群
回到控制面节点的终端,查看节点状态:
1 | kubectl get nodes |
Worker 节点会显示出来,ROLES 列为 <none>(这是正常的,worker 节点默认没有角色标签)。节点可能需要一分钟左右才能变成 Ready。
4. 确认所有 Pod 正常运行
1 | kubectl get pods --all-namespaces |
所有 Pod 都应该处于 Running 状态。注意每个节点上都会有 Calico 的 Pod 在运行,负责该节点的网络功能。
1 | ubuntu@ip-172-31-27-240:~$ kubectl get pods --all-namespaces |
双节点集群到这里就搭建完成了。
第四步:部署应用验证集群
集群搭好了,跑个 nginx 验证一下。
1. 创建 nginx Pod
1 | kubectl run nginx --image=nginx --port=80 |
2. 确认 Pod 运行正常
1 | kubectl get pods -o wide |
1 | ubuntu@ip-172-31-27-240:~$ kubectl get pods -o wide |
看 STATUS 是 Running,IP 已分配,记下 Pod 跑在哪个节点上。
3. 通过 NodePort 暴露服务
1 | kubectl expose pod nginx --type=NodePort --port=80 |
输出里 PORT(S) 列会显示类似 80:31973/TCP,31973 就是 NodePort。
4. 访问 nginx
1 | # 用 Pod 所在节点的 IP + NodePort |
1 | ubuntu@ip-172-31-27-240:~$ curl 172.31.16.97:32686 |
能看到 nginx 欢迎页就说明集群网络正常。
注意:NodePort 通过节点 IP 访问,不是 ClusterIP。ClusterIP 是集群内部的虚拟 IP,只在集群内部可达。
AWS 上的 Calico 网络踩坑
在 AWS EC2 上用 Calico 默认的 BGP 路由模式,你可能会发现从一个节点直接 curl 另一个节点上的 Pod IP 不通。比如从 master(10.0.0.100)curl worker 上的 Pod(192.168.180.194)会超时。
路由表是对的(ip route | grep 192.168 能看到到 worker Pod 网段的路由),但包就是过不去。
原因是 AWS VPC 的源/目标检查(Source/Destination Check)。EC2 默认会检查每个网络包的源 IP 和目标 IP 是否属于这台实例,Pod IP(192.168.x.x)不属于 EC2 的 VPC 地址,VPC 直接把包丢了。
关闭源/目标检查(简单)
AWS Console → EC2 → 选中实例 → Actions → Networking → Change source/destination check → Stop
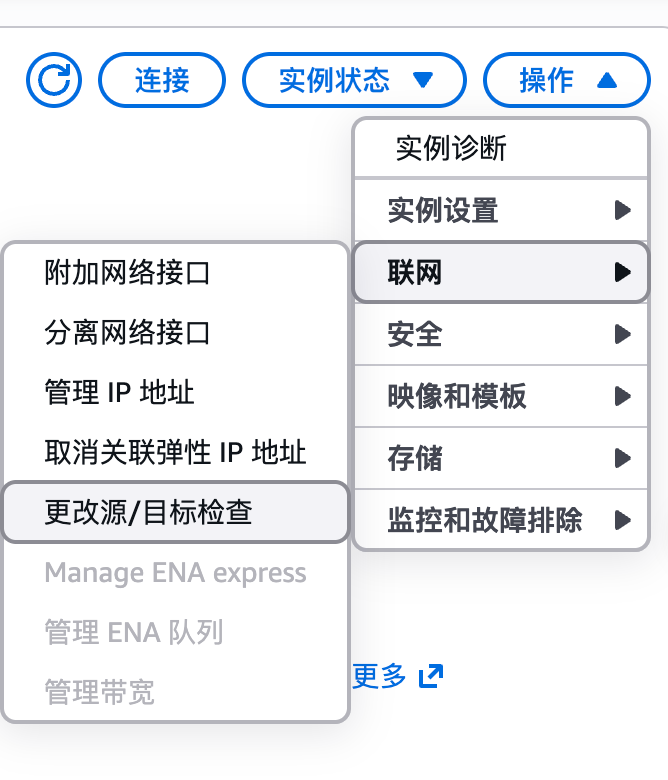
所有节点都要改。改完后跨节点的 Pod IP 直接访问就通了。
1 | ubuntu@ip-172-31-27-240:~$ curl 192.168.98.135 |
第五步:用 Deployment 管理副本
前面用 kubectl run 创建的是裸 Pod,不支持扩缩容。生产环境应该用 Deployment,支持副本管理和滚动更新。
1. 删掉裸 Pod,改用 Deployment
1 | kubectl delete pod nginx |
2. 查看副本状态
1 | kubectl get deployment nginx |
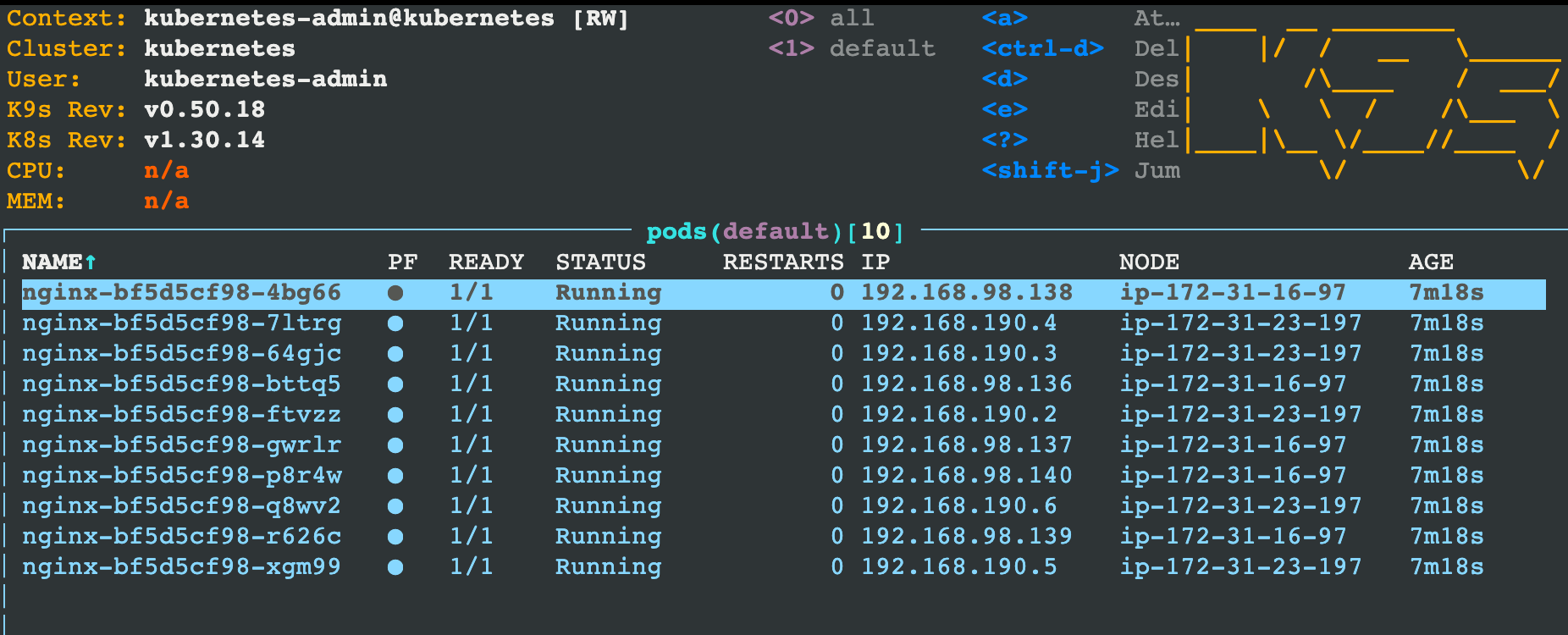
10 个 Pod 会分布在不同节点上。
3. 验证所有 Pod 都能访问
一行命令逐个 curl 所有 Pod IP:
1 | kubectl get pods -l app=nginx -o jsonpath='{range .items[*]}{.status.podIP}{"\n"}{end}' | while read ip; do echo "--- $ip ---"; curl --connect-timeout 3 -s $ip | head -1; done |
每个 IP 都输出 <!DOCTYPE html> 就说明都通了。
4. 调整副本数
1 | # 缩到 3 个 |
附:安装 k9s(终端集群管理工具)
k9s 是一个终端 UI 工具,比 kubectl 看集群状态直观很多,支持实时查看 Pod、日志、资源占用等。
Mac:
1 | brew install derailed/k9s/k9s |
Ubuntu/Linux:
1 | curl -sS https://webi.sh/k9s | sh |
或者直接下载二进制:
1 | curl -LO https://github.com/derailed/k9s/releases/latest/download/k9s_Linux_amd64.tar.gz |
装完敲 k9s 进入,按 : 输入资源类型(比如 pods、deploy、svc)切换视图从而看到集群的各种信息,q 退出。
在AWS EC2 上从零搭建 Kubernetes 集群(kubeadm)


