Easysearch 数据映射之 Deep Dive:我踩过的 Volume 坑
最近在用 Docker 部署 Easysearch,本以为是个简单的事情,结果在数据持久化上栽了跟头,每次停止再启动容器之后都会503,在后面成了我百思不得其解的问题,后来一直在某次的meetup中,请教了原厂的罗老师,一句话点醒梦中人,Easysearch用的具名卷,防止宿主机的数据覆盖容器里的数据。
Easysearch 数据映射之 Deep Dive:我踩过的 Volume 坑
最近在用 Docker 部署 Easysearch,本以为是个简单的事情,结果在数据持久化上栽了跟头,每次停止再启动容器之后都会503,在后面成了我百思不得其解的问题,后来一直在某次的meetup中,请教了原厂的罗老师,一句话点醒梦中人,Easysearch用的具名卷,防止宿主机的数据覆盖容器里的数据。
告别 DSL!我用 MCP 让 AI 帮我操作 Easysearch
还在为记不住 Elasticsearch DSL 语法发愁?match 和 term 傻傻分不清?聚合查询写半天还报错?
今天教你用 MCP(Model Context Protocol)封装 Easysearch,让 AI 帮你操作集群。从此告别 DSL,用自然语言就能完成搜索、写入、聚合统计!
先看看最终效果。以下是我和 Kiro 的真实对话记录:
我:集群健康吗?
Kiro:
1 | { |
🟢 集群很健康!状态 green,1 个节点,2 个活跃分片,100% 健康。
Easysearch 更新后日志中看不到密码?一文带你搞清楚原因与解决方案
最近在群里看到不少朋友反馈,Easysearch 升级到某个版本之后,日志文件里不再能看到初始化密码了。以前版本我们可以轻松在 /app/easysearch/logs/initialize.log 中找到,比如 exec 进入容器后直接 grep curl 搜索 Easysearch URI 字段,就能定位密码所在行。但现在——无论是 grep 还是手动翻,都空空如也。
过去版本,Easysearch 初始化时会将自动生成的默认密码打印到日志文件中。
如下图所示,这样的日志路径在老版本中非常常见:

在日常使用电脑的过程中,很多人习惯安装各种效率工具、启动器、播放器或日程管理应用。但这些功能其实都能被一个智能平台集中完成——这就是 Coco AI。
除了搜索和信息整理之外,Coco AI 还提供了一个完善的 插件系统。通过插件,它几乎可以控制电脑的方方面面:
操作本地备忘录、播放音乐、查找应用,甚至取代 macOS 的导航栏。更令人惊喜的是,它还内置小游戏,比如大家熟悉的 2048。
在 Elasticsearch 或者 Easysearch 这样的搜索引擎中,写入流程是理解性能调优和搜索可见性最核心的部分之一。许多同学刚接触 ES 时,最常见的疑惑就是:“为什么我刚插入的数据查不到?”、“refresh 和 flush 有什么区别?”、“refresh_interval 设置成多少合适?”
这篇文章我们就专门讲清楚 refresh(刷新) 这一环节。它是 ES 写入流程的关键节点,既影响了数据什么时候能被搜索到,也影响了整个系统的写入性能和稳定性。
Docker 启动 Easysearch 时自定义初始密码的几种方式
在使用 Docker 部署 Easysearch 时,通常需要在启动容器时设置初始管理员密码。如果没有预先设置密码,系统可能会使用默认值或随机生成密码,不仅增加后续管理的复杂性,也存在安全隐患。
本文将详细介绍在 docker run 启动 Easysearch 容器时,通过不同方式传入环境变量(env)来自定义密码的多种方法。每种方法都配有实用示例和说明,帮助你根据实际环境灵活选择。
不用每次都改 `easysearch.yml` 也能改启动参数 —— 用 Docker 环境变量搞定一切
在用 Docker 部署 Easysearch 的时候,很多人习惯性地去改容器里的 easysearch.yml。
但每改一次,就得重建镜像或重新挂载配置,既不方便,也不利于自动化。
其实,Docker 天生就支持通过环境变量来传递参数。
只要我们把要改的配置写进 .env 文件,再用 --env-file 加载,就能在启动时覆盖 easysearch.yml 的对应设置。
这样,既不用改镜像,也不用动配置文件,还能方便地调试、切换和管理。
Elasticsearch 自动 Mapping 与 MySQL Schema 的对比分析
在企业级数据系统中,Elasticsearch(简称 ES) 与 MySQL 是两种完全不同的数据管理哲学。
一个是面向搜索与分析的分布式引擎,一个是面向事务与一致性的关系型数据库。
而当我们深入理解它们的数据结构定义方式——ES 的 自动 mapping 推断 与 MySQL 的 手动 schema 定义——就会发现,它们的核心设计理念几乎是两个世界。
本文将从机制、原理、优缺点和使用建议等角度,系统对比两者的差异,重点聚焦在 Elasticsearch 的自动 mapping 特性上。
在 MySQL 中,我们习惯使用 表结构(Schema) 来定义数据字段及其类型:
1 | CREATE TABLE user ( |
每一行都必须严格遵守这个表结构,类型固定,字段不可缺少。
这是典型的 Schema-first 模型:在写入之前必须定义好结构。
而在 Elasticsearch 中,索引(Index)虽然也有 schema 概念,但它是通过 Mapping 来定义字段类型和分析方式的。
Mapping 可以手动声明,也可以让 ES 自动推断。例如:
1 | POST /user/_doc |
ES 会自动创建 user 索引,并根据字段值类型生成如下 mapping:
1 | { |
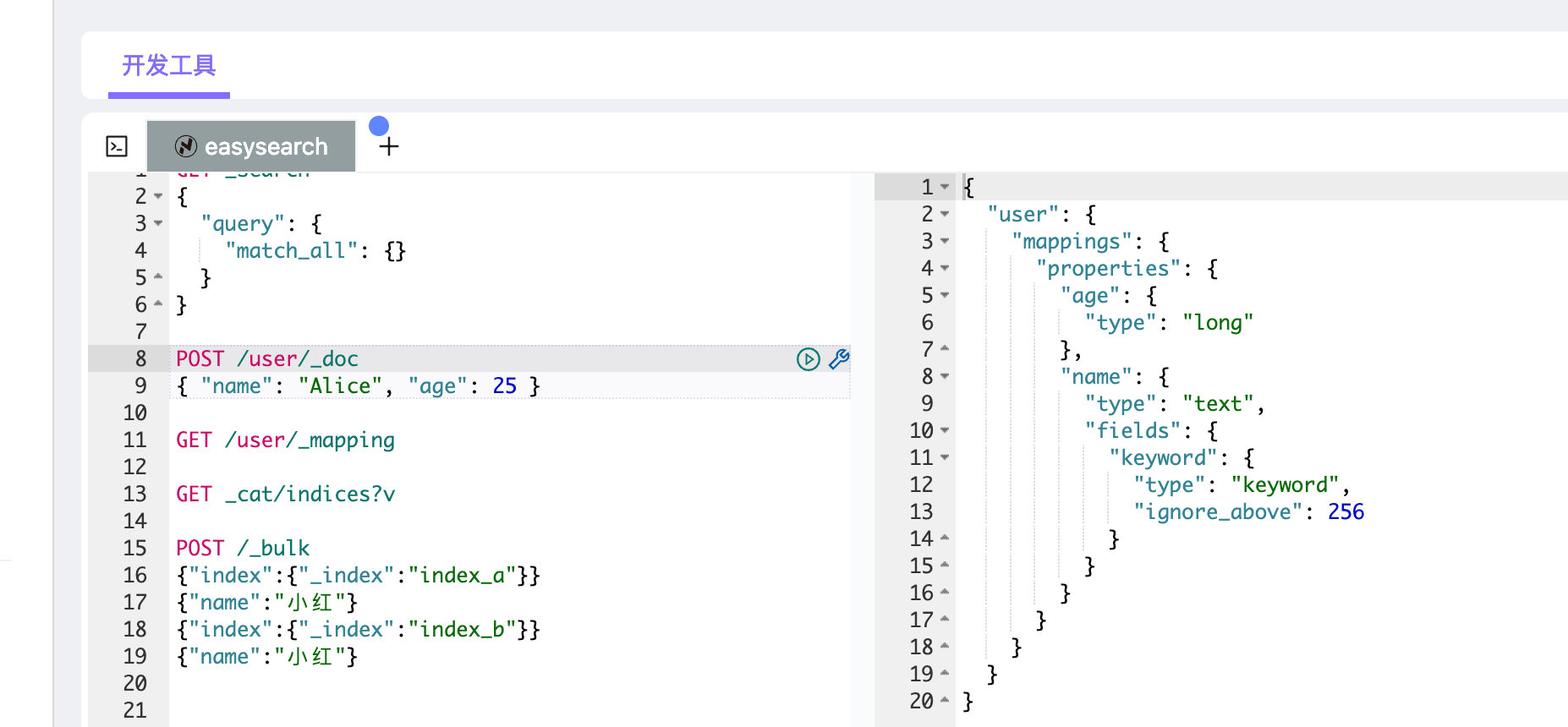
这就是 自动 mapping(dynamic mapping):ES 在第一次看到某字段时自动推断类型并写入 mapping。
不需要提前定义结构,系统“自学习”出 schema。
Elasticsearch 的 mapping 推断是动态的(Dynamic Mapping)。当写入新文档时,ES 会:
_mapping;例如:
| 值 | 推断类型 | 备注 |
|---|---|---|
"hello" |
text + keyword | 同时支持全文检索与精确匹配 |
123 |
long | 数值型 |
12.3 |
double | 浮点型 |
"2025-10-05" |
date | 自动识别日期格式 |
true |
boolean | 布尔值 |
ES 的这种自动识别让开发者在数据探索早期几乎零配置即可使用,非常便捷。
但这种便捷背后也隐藏着风险——错误推断、类型冲突、mapping 爆炸等问题可能在后期放大。
与 ES 不同,MySQL 属于 强类型、静态结构 模型。
它要求所有字段在写入前就被定义好。任何表结构变更都需要执行 ALTER TABLE,会产生锁表或重建索引的代价。
优点是:
缺点则是:
如果说 MySQL 的 schema 是“一座刚性大厦”,那 ES 的 mapping 就像“可随时扩建的集装箱”。
在日志、埋点、IoT 等场景中,数据字段极多且经常变化。
自动 mapping 让开发者无需提前规划字段,只要把 JSON 写进去,ES 就能立刻索引和查询。
例如日志:
1 | { "host": "server-1", "response_time": 123, "status": 200 } |
即使第二条日志多了新字段:
1 | { |
ES 也会自动为 region 增加字段定义,无需手动修改 mapping。
这在 MySQL 中则必须执行结构变更。
ES 的索引不要求所有文档字段一致。某些文档可以缺字段而不影响写入。
对动态 JSON 数据、日志、监控事件特别友好。
数据可来自多源系统(API、Kafka、日志流),字段差异大。
自动 mapping 让这些异构数据能快速进入索引,后期再统一分析。
在数据探索阶段,不必先定义 schema,就能立刻搜索和聚合,是数据科学家和分析工程师最喜欢的特性之一。
ES 根据值内容推断类型,但不是总能猜对:
| 原始值 | 被推断类型 | 潜在问题 |
|---|---|---|
"00123" |
text | 实际上是字符串数字 |
"2024/12/01" |
date | 格式异常可能被误识别 |
123.0 |
double | 实际希望 long,却被识别为浮点 |
true / false |
boolean | 可能来自字符串而非布尔值 |
类型一旦被推断并写入 mapping,就无法修改。
如果写错,只能重建索引并重新导入数据。
ES 的每个字段都要占用堆内存(field data、倒排索引、统计信息)。
当系统存在动态命名字段(如 user_1, user_2, …)时,会生成成千上万个字段,导致:
官方建议:单个索引字段数不要超过 1000。
ES 中字段一旦创建,类型就锁定。
比如第一次写入 "price": "123" 被识别为 text,之后再写入数字 price: 123 就会报错:
1 | mapper_parsing_exception: cannot merge a field of type [long] with [text] |
修复方法只有一个:重建索引。
自动 mapping 对 string 默认生成 text + keyword 两种字段。
在全文检索时 OK,但在聚合、排序、精确匹配时会引发困惑。
许多用户在 Kibana 中查询 "region.keyword" 才能聚合,是由 mapping 自动生成机制决定的。
相比之下,MySQL 的 schema 固定、类型严格,所有字段定义都在 DBA 控制下。
这意味着:
在交易、账务、库存、财务等场景中,MySQL 的稳定性远胜 ES。
它的缺点恰恰是 ES 的优点:灵活性差但可控。
ES 提供了几种方式,在保留灵活性的同时减少风险。
你可以为自动推断加“模板规则”:
1 | { |
这样所有 _id 结尾的字段都被强制识别为 keyword,而不是 text。
在生产环境常见做法是:
1 | { "dynamic": "strict" } |
意味着:未定义字段禁止写入。
防止误导入数据结构。
1 | PUT /my_index/_settings |
避免 mapping explosion。
对关键字段(时间戳、数值、地理位置、ID)手动声明类型。
剩余部分交由 dynamic mapping 自动处理,可兼顾灵活与安全。
| 指标 | Elasticsearch | MySQL |
|---|---|---|
| 写入性能 | 较高(分布式、异步) | 较低(事务同步) |
| 读取性能 | 适合全文检索、聚合分析 | 适合主键查询、范围查询 |
| schema 变更成本 | 无(自动) | 高(需 ALTER) |
| 内存消耗 | 较大(索引元数据) | 较小 |
| 数据一致性 | 弱一致 | 强一致 |
| 横向扩展性 | 强 | 中等 |
结论:
ES 的自动 mapping 提供了极高的写入灵活性,但代价是索引元数据膨胀、内存占用高、类型错误风险大。
MySQL 的 schema 则更适合结构化、高一致性业务。
| 场景 | 建议 |
|---|---|
| 日志、监控、埋点 | ✅ 开启自动 mapping(dynamic=true) |
| 搜索引擎、用户画像 | ✅ 自动 mapping + 动态模板 |
| 电商订单、金融账务 | ❌ 手动 mapping(dynamic=strict) |
| 混合型数据(部分稳定、部分动态) | ⚙️ 手动定义核心字段 + 动态模板控制扩展字段 |
| MySQL → ES 同步 | 🚫 禁止自动 mapping,使用 Logstash/ETL 生成预定义 mapping |
| 维度 | Elasticsearch 自动 Mapping | MySQL Schema |
|---|---|---|
| 定义方式 | 自动推断 | 手动定义 |
| 灵活性 | 极高 | 低 |
| 一致性 | 弱 | 强 |
| 修改成本 | 低(但错误代价高) | 高(但可控) |
| 可维护性 | 中等(需监控 mapping 爆炸) | 高 |
| 适用场景 | 搜索、日志、非结构化数据 | 交易、财务、结构化数据 |
Elasticsearch 的自动 mapping 是一把双刃剑:
它让数据“随写随用”,带来极大的灵活性;
但同时,也可能在规模化阶段埋下类型混乱、性能下降的隐患。
最佳实践是在项目早期利用其灵活性快速构建原型;
而在生产阶段,结合手动 mapping 与动态模板,建立“半自动、可控”的数据模型。
真正成熟的 ES 使用者,从来不会完全依赖自动 mapping。
自动化是起点,不是终点;灵活性需要以控制为前提。
Easysearch 索引别名(Index Alias)详解
在 Easysearch 中,索引别名(Index Alias) 是一种逻辑名称,它可以指向一个或多个真实索引。
使用别名的好处在于:
最近一段时间我折腾硬件比较多,经常翻箱倒柜找各种开发板出来玩。某天在角落里翻到一块嘉立创的泰山派开发板(Taishan Pi),这是一块基于 Rockchip RK3566 的嵌入式 Linux 板卡。严格来说,它的性能比树莓派还要逊色一些,尤其是 CPU 主频和内存带宽方面。但手痒之下,我突然想到了一个念头:能不能在这样一块嵌入式开发板上跑一个完整的 Easysearch 实例呢?
Easysearch 本质上是一个搜索引擎数据库,是 Elasticsearch 的国产化替代方案。它在大多数情况下被部署在 x86_64/arm 架构的服务器上,搭配 SSD 或 NVMe 作为存储,用来做全文检索、大规模日志分析或向量搜索。在常规的生产场景中,我们很少会把它和“嵌入式开发板”联想在一起。毕竟,后者 CPU 性能有限、内存紧张、存储设备大多是 eMMC 或低速 SD 卡,看起来完全不是数据库的适配环境。
Update your browser to view this website correctly.&npsb;Update my browser now